Chapter 6 of ALDA introduces strategies for fitting models in which individual change is discontinuous. This means the linear trajectory has a shift in the elevation and/or slope. To fit a model with discontinuous change we need to “include one (or more) time-varying predictor(s) that specify whether and, if so, when each person experiences the hypothesized shift.” (p. 191)
Some of the forms discontinuous change can take include:
- an immediate shift in elevation, but no shift in slope
- an immediate shift in slope, but no shift in elevation
- immediate shifts in both elevation and slope
- shifts in elevation (or slope) that differ in magnitude by time
- multiple shifts in elevation (or slope) during multiple epochs of time
The example in the book replicates work done by Murnane, et al. (1999). In their paper they analyzed wage data for high school dropouts and investigated whether (log) wage trajectories remained smooth functions of work experience. Their idea was that obtaining a GED might command a higher wage and thus cause a discontinuity in the linear model fit to the data. The authors partially replicate this work by fitting a taxonomy of multilevel models.
Here’s the data (courtesy of UCLA IDRE). The variables of interest are:
- id – person ID
- lnw – natural log of wages (the response)
- ged – indicator (1 = attained GED; 0 otherwise)
- exper – years in labor force to nearest day
- postexp – years in labor force from day of GED attainment
- hgc.9 – highest grade completed, centered on grade 9
- black – indicator (1 = black; 0 otherwise)
- ue.7 – unemployment rate, centered on 7%
The initial model is rather elaborate due to earlier work in the book. Using the book’s notation we state the level-1 and level-2 models as follows:
Level-1
Level-2
Where,
and
 + \epsilon_{ij}")
 + \xi_{0i}")




What a mess. Let’s break this down. The level-1 model is the individual growth model. It posits an individual’s wages can be explained by his years in the labor force (EXPER) and the unemployment rate (UE). The level-2 model says
- the intercept in the level-1 model varies by highest grade completed (HGC)
- the EXPER coefficient in the level-1 model varies based on whether or not your race is black (BLACK)
- the UE coefficient is fixed for all individuals
If we collapse the two levels into one model we get
 + \gamma_{10}EXPER_{ij} + \gamma_{12}EXPER_{ij} \times BLACK_{i} + \gamma_{20}(UE_{ij}-7) + \xi_{0i} + \xi_{1i}EXPER_{ij} + \epsilon_{ij}")
That’s not exactly fun to look at either, but the last few terms reveal the random effects. The 


We can fit this model in R as follows:
wages <- read.table("http://www.ats.ucla.edu/stat/r/examples/alda/data/wages_pp.txt",
header=T, sep=",")
library(lme4)
model.a <- lmer(lnw ~ exper + hgc.9 + exper:black + ue.7 + (exper|id),
wages, REML=FALSE)
The key part is the stuff in the parentheses. It says EXPER - and the intercept by default - are the random effects, and that they're grouped by ID (ie, the individuals). This means that each individual has his own intercept and EXPER coefficient in the fitted model. Let's look at the model's fixed effects and the random effects for individual 1.
The model's fixed effects:
fixef(model.a) (Intercept) exper hgc.9 ue.7 exper:black 1.74898840 0.04405394 0.04001100 -0.01195050 -0.01818322
Random effects for first individual (ID = 31) in data:
ranef(model.a)$id[1,] (Intercept) exper 31 -0.1833142 0.02014632
To see the final model for this individual we add his random effects to the fixed effects:
ranef(model.a)$id[1,] + fixef(model.a) (Intercept) exper 31 1.565674 0.06420026
Or we can just do this:
coef(model.a2)$id[1,] (Intercept) exper hgc.9 ue.7 exper:black 31 1.565674 0.06420026 0.040011 -0.0119505 -0.01818322
Notice how the intercept and EXPER coefficient are different for the individual versus the fixed effects. Now we're usually less interested in the specific random effects (in this case there are 888 of them!) and more interested in their variances (or variance components). The variance component for the intercept is 0.051. The variance component for EXPER is 0.001. Those are pretty small but not negligible.
Having said all that, the goal of this exercise is to build the best model with discontinuities, which is largely done by deviance statistics. So let's work through the book's example and remember that everything I explained above is the baseline model. All subsequent models will build upon it.
The first model up adds a discontinuity in the intercept by including fixed and random effect for GED:
model.b <- lmer(lnw ~ exper + hgc.9 + exper:black + ue.7 + ged +
(exper + ged|id), wages, REML=FALSE)
anova(model.a,model.b)
To get a feel how GED affects the model, look at the records for individual 53:
wages[wages$id == 53,1:4] id lnw exper ged 19 53 1.763 0.781 0 20 53 1.538 0.943 0 21 53 3.242 0.957 1 22 53 1.596 1.037 1 23 53 1.566 1.057 1 24 53 1.882 1.110 1 25 53 1.890 1.185 1 26 53 1.660 1.777 1
Notice how GED flips from 0 to 1 over time. Model B allows an individual's wage trajectory to shift in "elevation" at the point GED changes to 1. Hence the discontinuity. Should we allow this? Calling anova(model.a,model.b) helps us decide. In the output you'll see the p-value is less than 0.001. The null here is no difference between the models, i.e., the new explanatory variable in model B (GED) has no effect. So we reject the null and determine that an individual's wage trajectory may indeed display a discontinuity in elevation upon receipt of a GED.
Our next model is model B without GED random effects:
model.c <- lmer(lnw ~ exper + hgc.9 + exper:black + ue.7 +
ged + (exper|id), wages, REML=FALSE)
anova(model.c,model.b)
This is our baseline model with an additional fixed effect for GED. Should we include random effects for GED? Again we test the null that there is no difference between model B and C by calling anova(model.c,model.b). Since model C is nested in model B and the p-value returned is about 0.005, we reject the null and decide to keep the GED random components.
The next two models explore a discontinuity in the slope of the wages trajectory but not the elevation. We do this by removing the GED fixed and random effects and replace them with POSTEXP fixed and random effects. Recall that POSTEXP is years in labor force from day of GED attainment. To see how it works, look at the records for individual 4384:
wages[wages$id == 4384,3:5]
exper ged postexp
2206 0.096 0 0.000
2207 1.039 0 0.000
2208 1.726 1 0.000
2209 3.128 1 1.402
2210 4.282 1 2.556
2211 5.724 1 3.998
2212 6.024 1 4.298
The record where GED flips to 1 is the day he obtains his GED. The next record clocks the elapsed time in the workforce since obtaining his GED: 1.402 years. POSTEXP records this explicitly. But that's what EXPER records as well: 3.128 - 1.726 = 1.402. So these two variables record the passage of time in lockstep. It's just that EXPER records from the "beginning" and POSTEXP records from the day of GED attainment. Allowing this additional variable into the model allows the slope of the wages trajectory to suddenly change when a GED is obtained. OK, enough talking. Let's see if we need it.
model.d <- lmer(lnw ~ exper + hgc.9 + exper:black + ue.7 + postexp +
(exper + postexp|id), wages, REML=FALSE)
anova(model.d,model.a)
The p-value returned from the anova function is about 0.01. This says model D is an improvement over model A and that the trajectory slope of wages indeed changes upon receipt of GED.
The next model is model D without random effects for POSTEXP. So whereas previously we allowed the change in slope to vary across individuals (random), now we're saying the change in slope is uniform (fixed) for all individuals. In the R code this means removing POSTEXP from the random effects portion but keeping it as a fixed effect.
model.e <- lmer(lnw ~ exper + hgc.9 + exper:black + ue.7 + postexp +
(exper|id), wages, REML=FALSE)
anova(model.d,model.e)
The results from this anova test conclude no difference between the models (p-value = 0.34). This means we may not need to allow for POSTEXP random effects.
But before we go with that, let's fit a model that allows for discontinuity in both the slope and elevation of the individuals' wages trajectory. In other words, let's throw both GED and POSTEXP in the model as both fixed and random effects. And then let's compare the model with previous models to determine whether or not to keep each predictor.
model.f <- lmer(lnw ~ exper + hgc.9 + exper:black + ue.7 +
postexp + ged + (postexp + ged + exper|id),
wages, REML=FALSE)
# compare models f and b to evaluate POSTEXP effect (NULL: no POSTEXP effect)
anova(model.b,model.f)
# compare models f and d to evaluate GED effect (NULL: no GED effect)
anova(model.d,model.f)
In both anova tests, the p-values are very small, thus we reject the null in each case and retain the predictors. Therefore it appears that in the presence of the GED predictor that we do actually want to retain random effects for POSTEXP. But we're not done yet. Let's fit two more models each without the POSTEXP and GED random effects, respectively, and compare them to model F:
# MODEL G - Model F without POSTEXP variance component
model.g <- lmer(lnw ~ exper + hgc.9 + exper:black + ue.7 +
postexp + ged + (ged + exper|id), wages, REML=FALSE)
# MODEL H - Model F without GED variance component
model.h <- lmer(lnw ~ exper + hgc.9 + exper:black + ue.7 +
postexp + ged + (postexp + exper|id), wages, REML=FALSE)
deviance(model.h)
# compare models g and h to model f to see if we should
# keep POSTEXP and GED variance components
# NULL: do not need variance components
anova(model.g,model.f)
anova(model.h,model.f)
In both anova tests we get p-values less than 0.01 and reject the null. We should indeed keep the random effects. So our final model allows for both discontinuities in elevation and slope in the individuals' trajectories. Here's a super rough way we can visualize this in R:
# visual aid of discontinuity in slope and elevation # made up model coefficients b0 <- 3 b1 <- 5 b2 <- 2 b3 <- 4 # variables ind <- c(rep(0,10),rep(1,11)) # indicator of event time <- c(1:10,10,11:20) # time time2 <- c(rep(0,11),1:10) # additional time tracking after event occurs # create response y <- b0 + b1*ind + b2*time + b3*time2 # plot response versus time plot(time, y, type="l")
This gives us the following line plot:
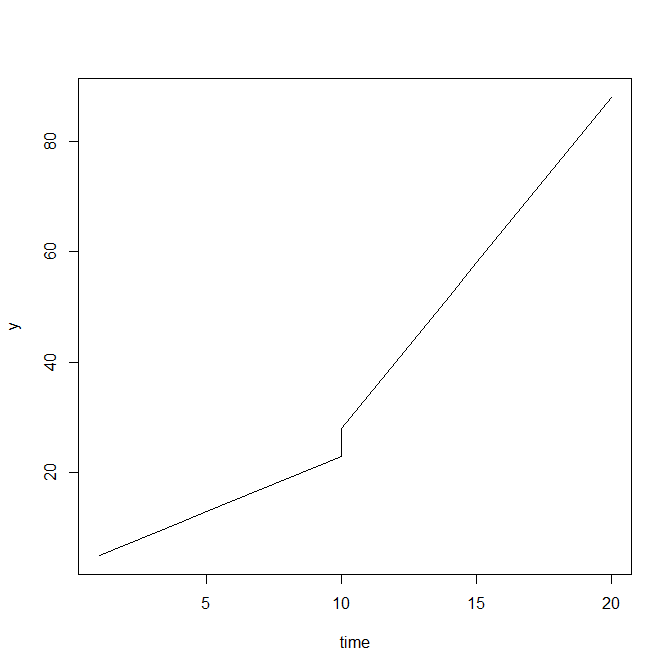
Notice the shift in elevation at 10 and then the change in slope after the shift in elevation.
















 . When program = 1, our linear model is
. When program = 1, our linear model is  . The intercept in these models is interpreted as the cognitive score at the first measurement (when the infants were 12 months old). We can see that infants in the program had a higher performance at the first measurement than those not in the program: 114.69 – 107.84 = 6.85. The slope tells us the rate of decline of cognitive performance (decline?). We see the infants in the program had a slower rate of decline over time: -15.86 versus -21.13. Or put another way: -21.13 – -15.86 = -5.27, which is the coefficient of the interaction. That is, the difference in slopes between the two groups is -5.27.
. The intercept in these models is interpreted as the cognitive score at the first measurement (when the infants were 12 months old). We can see that infants in the program had a higher performance at the first measurement than those not in the program: 114.69 – 107.84 = 6.85. The slope tells us the rate of decline of cognitive performance (decline?). We see the infants in the program had a slower rate of decline over time: -15.86 versus -21.13. Or put another way: -21.13 – -15.86 = -5.27, which is the coefficient of the interaction. That is, the difference in slopes between the two groups is -5.27.")
")
")